*Welcome page*

left join是保留左表v_tray_total_size所有记录(右表多余字段alloc_size当与左表store_id, tray_uuid都匹配记录时合并; 左表多余字段status保留, 共同字段total_size, store_id, tray_uuid)store_id 和 tray_uuid 都匹配的记录时,就会将右表的 alloc_size(已分配容量)合并到结果中;当右表中没有匹配的记录(比如该托盘从未分配过空间),右表的 alloc_size 会显示为 NULL,但通过 COALESCE(a.alloc_size, 0) 会将其转换为 0,确保后续计算 free_size 时正确(总容量 - 0 = 总容量)。举个例子帮助理解:
- 左表 v_tray_total_size(t) 有两条记录:
| store_id | tray_uuid | total_size | status |
| s1 | t1 | 1000 | OK |
| s1 | t2 | 2000 | OK |
- 右表 v_tray_alloc_size(a) 只有一条记录(t1 有分配,t2 未分配):
| store_id | tray_uuid | alloc_size |
| s1 | t1 | 300 |
- 通过 LEFT JOIN 关联后,结果会是:
| store_id | tray_uuid | total_size | alloc_size(合并右表) | free_size | status |
| s1 | t1 | 1000 | 300(右表匹配到) | 700 | OK |
| s1 | t2 | 2000 | 0(右表无匹配,COALESCE 处理) | 2000 | OK |
哪里涉及alloc_size、shard_size
- 这个计算空间除了初始化init数据库的时候,在更新增删节点
add_storenode,新增volume会用到,还有啥地方会涉及 - 这个shard_size的计算好像只在
do_create_volume和do_create_pfs2里面有... v.shard_size = Config.DEFAULT_SHARD_SIZE; ... long shardCount = (v.size + v.shard_size - 1) / v.shard_size; ... assert(v.shard_size == 1L<<reply.shard_lba_cnt_order); ...系统应该采取了预分配,有
prepare_volume方法
好像系统分配方法是先不管实际占用alloc多少空间固定分配64G,无论是实际还是docker情况;都不是实际写入多少
AI猜测验证
猜测: 一个卷(t_volume)的分片(shard)可能被复制到多个副本(t_replica),导致 shard_size 被重复统计。
-- v_tray_alloc_size
select store_id, uuid as tray_uuid, raw_capacity as total_size, status from t_tray;
多副本本身没错,错误出在 “副本分配时未限制单个托盘的总分配容量”,而视图 v_tray_alloc_size 如实统计了每个托盘上所有副本的物理占用,最终导致 alloc_size 超过 total_size.
MariaDB [s5]>
SELECT v.id AS volume_id,v.shard_size, COUNT(r.id) AS replica_count, -- 该卷的总副本数
v.shard_size * COUNT(r.id) AS total_allocated -- 被累加的总大小
FROM t_volume v
JOIN t_replica r ON v.id = r.volume_id
WHERE v.id = '2030043136' GROUP BY v.id, v.shard_size;
+------------+-------------+---------------+-----------------+
| volume_id | shard_size | replica_count | total_allocated |
+------------+-------------+---------------+-----------------+
| 2030043136 | 68719476736 | 30 | 2061584302080 |
+------------+-------------+---------------+-----------------+

看空间数据是怎么来的
一定是真正写入数据了,才占用空间的
一开始分配的时候都没有写入数据,只是分配了64G的shard(比如do_create_volume中的相关代码)
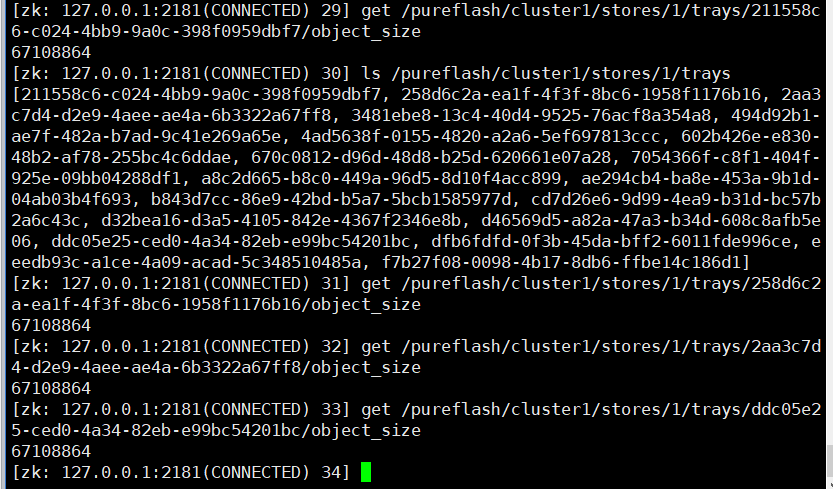
zk里面所有的object_size都是64G
25.10.23结论
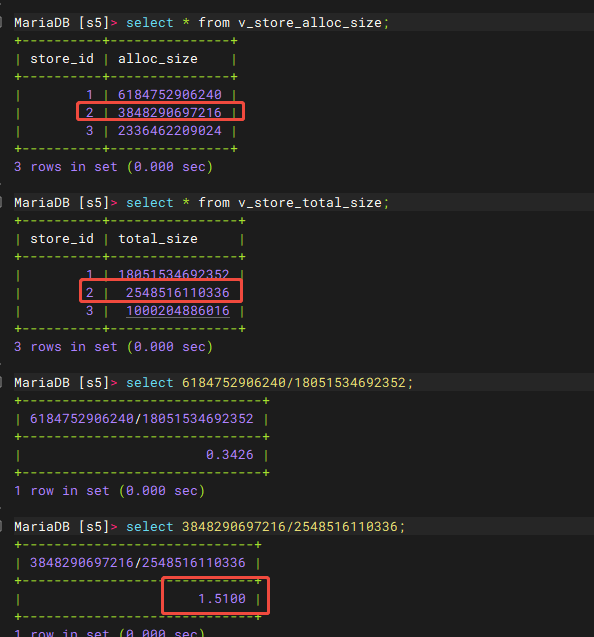
问题描述:下图中的v_store_total_size小于v_store_alloc_size
问题相关代码:
create view v_store_alloc_size as select store_id, sum(t_volume.shard_size) as alloc_size from t_volume, t_replica where t_volume.id=t_replica.volume_id group by t_replica.store_id;
create view v_store_total_size as select s.id as store_id, sum(t.raw_capacity) as total_size from t_tray as t, t_store as s where t.status="OK" and t.store_id=s.id group by store_id;
结论:
| v_store_alloc_size是根据之前预分配的大小来的,没有存储实际分配大小;v_store_total_size只计算了状态为OK的大小,掉线的盘不计算;
因此当节点掉线,已分配的空间不会变,但总空间变小了,问题产生
注:因为v_store_total_size计算没有包含状态掉线的盘(offline),所以该问题与’t_tray表格里有冗余tray信息’问题不相关.